RabbitMQ
高级消息队列(Advanced Message Queuing)模型,RabbitMQ 实现了 AMQP 协议
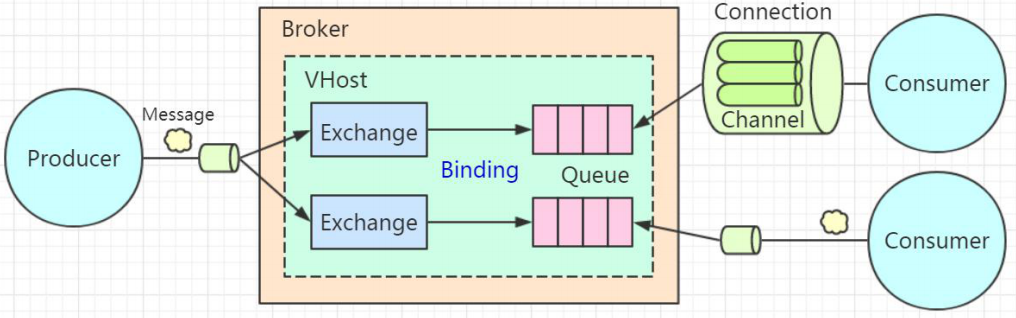
RabbitMQ概念
Broker
机节点,中文翻译是代理/中介,因为 MQ 服务器帮助我们做的事 情就是存储、转发消息
Connection
无论是生产者发送消息,还是消费者接收消息,都必须要跟 Broker 之间建立一个连接,这个连接是一个 TCP 的长连接
Channel
如果所有的生产者发送消息和消费者接收消息,都直接创建和释放 TCP 长连接的话, 对于 Broker 来说肯定会造成很大的性能损耗,因为 TCP 连接是非常宝贵的资源,创建和释放也要消耗时间
所以在 AMQP 里面引入了 Channel 的概念,它是一个虚拟的连接。我们把它翻译成通道,或者消息信道。这样我们就可以在保持的 TCP 长连接里面去创建和释放 Channel,大大了减少了资源消耗。
另外一个需要注意的是,Channel 是 RabbitMQ 原生 API 里面的最重要的编程接口,也就是说我们定义交换机、队列、绑定关系,发送消 息消费消息,调用的都是 Channel 接口上的方法
Queue
队列是真正用来存储消息的,是一个独立运行的进程,有自己的数据库(Mnesia)
消费者获取消息有两种模式,一种是 Push 模式,只要生产者发到服务器,就马上推送给消费者。另一种是 Pull 模式,消息存放在服务端,只有消费者主动获取才能拿到消息。消费者需要写一个 while 循环不断地从队列获取消息吗?不需要,我们可以基于事件机制,实现消费者对队列的监听
由于队列有 FIFO 的特性,只有确定前一条消息被消费者接收之后,才会把这条消息 从数据库删除,继续投递下一条消息
三种抽象组件用于指定消息的路由行为:
Exchange
交换机是一个绑定列表,用来查找匹配的绑定关系
队列使用绑定键(Binding Key)跟交换机建立绑定关系。 生产者发送的消息需要携带路由键(Routing Key),交换机收到消息时会根据它保存的绑定列表,决定将消息路由到哪些与它绑定的队列上。
注意:交换机与队列、队列与消费者都是多对多的关系
Vhost
我们每个需要实现基于 RabbitMQ 的异步通信的系统,都需要在服务器上创建自己要用到的交换机、队列和它们的绑定关系。如果某个业务系统不想跟别人混用一个系统,怎么办?再采购一台硬件服务器单独安装一个 RabbitMQ 服务?这种方式成本太高了。
在同一个硬件服务器上安装多个 RabbitMQ 的服务呢?比如再运行一个 5673 的端口? 没有必要,因为 RabbitMQ 提供了虚拟主机 VHOST
VHOST 除了可以提高硬件资源的利用率之外,还可以实现资源的隔离和权限的控制。它的作用类似于编程语言中的 namespace 和 package,不同的 VHOST 中可以有同名的 Exchange 和 Queue,它们是完全透明的。
我们可以为不同的业务系统创建不同的用户(User),然后给这些用户分配 VHOST 的权限。比如给风控系统的用户分配风控系统的 VHOST 的权限,这个用户可以访问里面的交换机和队列。给超级管理员分配所VHOST的权限
Queue的绑定
将queue绑定到exchange上时,会指定一个BindingKey
生产者消息发送到exchange,会携带一个routerKey
exchange将根据消息的routerKey路由到已绑定的且BindingKey匹配的queue上
Exchange类型
- Direct exchange
交换机路由消息,要精确匹配routerKey,即消息的routerKey与绑定queue的routerKey要完全一致
Topic exchange
queue的routerKey中含有通配符,交换机路由消息,只要消息的routerKey能匹配topic patten就能路由
#表示0个或多个word
*表示不多不少一个word
如果queue指定的routerKey是 : #.panda.*,则消息的routerKey为 panda.txt zhao.panda.name zhao.test.panda.zzk 这些都能路由到该queue中
- Fanout exchange
扇形交换机,queue与其绑定时不需要指定routerKey,生产者向该类exchange发送消息时也不用携带routerKey,该类交换机会将收到的消息广播给所有的与其绑定的queue。
- headers
不依赖路由键的匹配规则分发消息,而是根据发送的消息内容的headers属性进行匹配。
在绑定队列和交换器时制定一组键值对,当发送消息到交换机的时候,rabbitmq会获取该消息的headers,对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对。
如果完全匹配消息就会路由到该队列,否则不会路由到该队列
谁来创建队列和交换机?
回顾前面的基本架构图,这个架构中生产者和消费者能正常工作的一个重要前提是,所有这些RabbitMQ基础设施(即queue、exchange和绑定关系)必须是已经存在的。生产者无法发布消息给一个不存在的exchange,也不可能有消费者从一个不存在的队列中获取消息
因此,让生产者或消费者在发送和接收消息之前创建exchange、queue和bindings并不是不合理的,让我们来看一下具体如何实现,并且思考下每种方法的影响。
生产者创建exchange
生产者和消费者完全解耦,理想情况下,生产者应该知道只知道exchange(而不是queue),并且消费者应该只知道queue(不是exchange),bindings是exchange和queue之前的胶水
一个可行的方法是由生产者处理exchange的创建,然后消费者创造他们所需要的队列并将其绑定到exchange。
这种分离策略的优点是,当消费者需要新队列时,只需要根据需要创建队列并绑定,不需要生产者需要了解他们。这不是完全解耦,消费者必须知道exchange的存在以绑定它。
另一方面,有一个非常确实的危险。如果在消费者部署之前,有任意消费者正在运行,那么exchange就无法绑定,这样生产者启动后发出的所有消息都将丢失。这需要系统实际情况来决定是否是可接受的。
生产者创建一切
生产者可以配置成在启动时创建所有必要的基础设施(exchange、queue和bindings)。这有一个好处,那就是消息将不会因为queue和exchange没有绑定而丢失(因为queue绑定到exchange不需要任何消费者先运行)。
然而,这意味着生产者必须知道所有的queue,这并不是一个解耦的方法。每次添加新queue,生产者必须重新配置和部署创建绑定它。
消费者创建一切
相反的方法是让消费者在启动的时候创建一切。像前面的方法一样这种方法也存在耦合,因为消费者必须知道他们的queue和哪个exchange绑定。exchange的任何改变(例如重命名)都意味着所有消费者都必须重新配置和重新部署。这种复杂性可能会导致项目无法使用大量的queue和消费者。
不创建任何东西
一个完全不同的选择是生产者和消费者不创建任何所需的基础设施。相应地,由用户界面管理插件Management Plugin 和 Management CLI 来创建和绑定。这样做有几个好处:
生产者和消费者可以真正的解耦。生产者只了解exchanges,消费者只知道队列。- 这可以很容易地部署脚本和自动化通道。
- 任何更改(如新
队列)可以直接添加,而不需要触及任何现有的,已经部署的生产者和消费者。
AMQP帧
启动会话
RabbitMQ 通过 Connect.Start 命令响应问候语
Client 使用 Connect.StartOk 来响应
要完全连接到 RabbitMQ 需要完成由3个同步RPC请求所组成的序列,启动、调整、打开链接
一个 AMQP 连接可以有多个信道,允许客户端和服务器进行多次会话(多路复用)
信道不是越多越好,每个信道都会设置内存结构和对象,连接中的信道越多,RabbitMQ 用于管理该连接的消息流所需的内存也就越多
帧类型
协议头帧:用于连接到 RabbitMQ,仅使用一次
方法帧:携带发送给 RabbitMQ 或从 RabbitMQ 接收到的RPC请求或响应(类、方法、相关参数)
内容头帧:包含一条消息的大小和属性(Basic.Properties)
消息体帧:包含消息的内容,不进行任何编码和打包,JSON、XML等数据格式
心跳帧:保活
发布到 RabbitMQ 的单个消息由三种帧类型组成:供
Basic.PublishRPC调用的方法帧、消息头帧、以及一个或多个消息体帧
Basic.Publish 方法帧由五个组件构成:标识请求的类、方法类型、交换器名称、路由键、mandatory
Mandatory 标志告知 RabbitMQ 消息必须投递成功,否则就是失败的
帧的默认大小为131KB,但是可以在连接过程中协商,最大32位值的字节
AMQP 默认通信规则:成功无返回
- 信道编号
- 以字节为单位的帧大小
- 帧有效载荷
- 结束字节标记(ASCII值206 0xce)
使用协议
使用 Exchange.Declare 命令创建交换器,创建成功后 Exchange.DeclareOk 响应,失败 Channel.Close 关闭信道
Queue.Declare 命令创建队列,成功 Queue.DeclareOk,失败 Channel.Close 关闭信道
多次发送同一个 Queue.Declare 命令不会有任何副作用,会返回队列相关的信息
如果新声明的队列与现有队列同名,但是属性不一样,RabbitMQ 将关闭信道
所以需要客户端监听来自 RabbitMQ 的Channel.Close响应,如果没有正确处理来自服务器的事件,则可能发生丢失消息。
例如向一个不存在或者已关闭的信道发送消息,RabbitMQ会关闭连接,如果客户端不知道RabbitMQ已经关闭了连接,可能导致订阅空队列
Queue.Bind 命令将队列绑定到交换器,成功响应 Queue.BindOk
Basic.Publish 发送消息,默认情况下发布到不存在的交换器,RabbitMQ 会自动丢弃该消息,确保消息发送成功需要将mandatory标志设置为true
或者使用投递确认机制,当 RabbitMQ 发现某一个交换器与 Basic.Properties方法帧只能的交换器名称相匹配时,它将判断该交换器中的绑定信息,并通过路由键
寻找匹配的队列。当消息与任一队列匹配时,放入队列(放入队列的数据结构是消息的引用)
Basic.Consume命令订阅消息, Basic.ConsumeOk 响应并释放至少一条信息
消费者将开始通过Basic.Deliver方法和它们的内容头以及消息体接收消息
Basic.Cancel 命令停止接收消息,在收到Basic.CancelOk 前仍然可以接收 RabbitMQ 预分配的消息
Basic.Consume命令中的no_ack参数设置为true时,RabbitMQ将连续发送消息,直到消费者发送Basic.Cancel 命令
如果no_ack参数设置为false,则必须通过Basic.Ack来确认接收到的每条消息,当发送Basic.Ack时,消费者必须在Basic.Deliver方法帧中传递
一个名为delivery tag的参数,RabbitMQ使用投递标签和信道作为唯一标识符来实现消息确认、拒绝、否定确认
Properties
包含在消息头帧中的消息属性是一组预定义的值,通过
Basic.Properties数据结构进行指定
- content-type
让消费者知道如何解释消息体,最好明确指定,不隐式,例如
application/json - expiration
消息过期,如果消息没有被消费,可以告诉 RabbitMQ 何时丢弃消息(字符串的时间戳)
- reply-to
实现响应消息的路由,可以构建一个用来回复消息的私有响应队列
- content-encoding
指定消息体的压缩或编码,例如
gzip - delivery-mode
指定消息保存到内存前,是否必须先存储到磁盘(2表示持久化 1表示非)
- headers
定义自由格式的属性和实现路由,键为ASCII或者Unicode字符串255,值可以是任何有效的AMQP值类型
可以根据headers表中填充的值路由消息,而不需要依赖路由键 - message-id
唯一标识消息和响应消息,用于实现消息跟踪,correlation-id类似,255字节UTF-8编码数据
- app-id
标识消息发布者,用来追踪、统计、版本,user-id类似,255字节UTF-8编码数据
- priority
优先级,0-9,0优先级最大,虽然是0-255但是规范指定为0-9
- correlation-id
指定该消息是另一个消息的响应,关联message-id
- user-id
会根据认证的用户信息来检查每条已发布的消息的user-id,如果不匹配,则该消息被拒绝
- cluster-id
不建议使用
- timestamp
创建时间,可以用来评估消息投递过程的性能
- type
定义发布者和消费者之间的契约,创建字描述消息时,type属性非常有用
消息发布性能
- 消息发布时保证消息进入队列的重要性有多高?
- 如果消息无法路由,是否应该将其发送到其他地方稍后进行重新路由?
- 如果 RabbitMQ 服务器崩溃,可以接受消息丢失吗?
- RabbitMQ 在处理新消息时是否应该确认它已经为发布者执行了所有请求路由和持久化任务?
- 消息发布者是否可用批量投递消息,然后从 RabbitMQ 收到一个确认用于表明所有请求的路由和持久化任务已经批量应用到所有的消息中?
- 如果要批量发布消息,并且这些消息需要确认路由和持久化,那么对每一条消息是否需要对目标队列实现真正意义上的原子提交?
- 在可靠投递方面是否有可以接受的平衡性,你的发布者可以使用它来实现更高的性能和消息吞吐量吗?
- 消息发布还有哪些方面会影响消息的性能和吞吐量?
mandatory
告诉 RabbitMQ 如果消息不可路由,它应该通过
Basic.Return命令将消息返回给发布者(失败才会通知)
发布确认
事务的轻量级替代方法,发布任何消息之前,消息发布者必须向 RabbitMQ 发出
Confirm.Select请求,并等待Confirm.SelectOk响应,这样才算投递确认已启动
无论是否使用发布者确认,如果发布的消息匹配不到交换器,那么发布通道将被关闭
备用交换器
备用交换器在第一次声明交换器时被指定,用来提供一种预先存在的交换器,如果交换器无法路由消息,那么消息就会被路由到这个新的备用交换器(发布成功)
事务
TX.Select TX.SelectOk TX.Commit TX.CommitOk TX.Rollback TX.RollbackOk
RabbitMQ 只在每个发出的命令作用于单个队列时才执行原子任务(很难控制)
HA队列
允许队列在多个服务器上拥有冗余副本,HA队列有一个主服务节点,其他所有节点都是辅助节点,如果主节点发送故障,其中一个辅助节点将接管主节点
辅助节点宕机,其它节点照常运行,新节点添加到集群时,它将不包含任何已存在的信息
阻塞发送
如果因为发布消息太快而开始对 RabbitMQ 造成压力,那么 RabbitMQ 将发送
Channel.Flow来阻塞发布者,直到收到另一条Channel.Flow命令为止
RabbitMQ 使用一种TCP背压(backpressure)的机制来解决这个问题,停止接受TCP套接字上的底层数据
新连接建立时,连接将被分配一个预定数量的可用信用值,然后每接收一条命令,扣除一点信用值,命令处理完毕则返还信用值,RabbitMQ根据信用值余额来确认是否从TCP读取数据
3.2版本开始,添加了在达到连接信用阈值时发送通知的机制, Connection.Blocked 和 Connection.Unblocked 这是异步的
一旦遇到阻塞说明我们的 RabbitMQ 遇到了问题,可能需要考虑扩容了
消息消费
对比 Basic.Get Basic.Consume
Get 是轮询模型,Consume 是推送模型
- Get
每次都需要发送新的请求来获取消息,有很大的通信开销,而且 RabbitMQ 没有办法优化整个投递的过程,因为它永远不知道应用程序会何时请求消息
- Consume
一旦有消息 RabbitMQ 就会进行推送,直到客户端发出一个 Basic.Cancel 为止
应用程序发出 Basic.Consume 时会创建一个唯一的字符串(消费者标签), RabbitMQ 每次都会把该字符串与消息一起发送给应用程序, Basic.Cancel 命令可以使用消费者标签来取消获取消息
优化消费者性能
- 使用
no-ack模式
收到消息时不进行确认,效率快,但是也是最不可靠的方式
- QoS 控制消费者预取
与no-ack不同,如果消费者在确认消息之前奔溃,则在socket关闭时,所有预取的消息将返回到队列
可以设置 Basic.Ack 的 multiple=true 属性来确认以前所有未确认的信息,也有一个风险就是如果处理一部分消息,然后消费者奔溃了没有确认,那么处理过的消息也会返回队列
拒绝消息
Basic.Reject Basic.Nack 可以将消息踢回服务器,Nack可以一次拒绝多个消息
- 死信交换器
一旦拒绝了一个不重新发送的消息 RabbitMQ 将把消息路由器到队列的 x-dead-letter-exchange 参数指定的交换器(与备用交换器不一样,备用交换器是路由无法由 RabbitMQ 路由的信息)
控制队列
队列的设置是不可变的,如果要改变,只能删除后重新创建
使用
用户角色和权限
user 有5种 tags :
- management :访问 management plugin
用户可以通过AMQP做的任何事外加:
列出自己可以通过AMQP登入的virtual hosts
查看自己的virtual hosts中的queues, exchanges 和 bindings
查看和关闭自己的channels 和 connections
查看有关自己的virtual hosts的“全局”的统计信息,包含其他用户在这些virtual hosts中的活动 - policymaker :访问 management plugin 和管理自己 vhosts 的策略和参数
management可以做的任何事外加:
查看、创建和删除自己的virtual hosts所属的policies和parameters - monitoring :访问 management plugin 和查看所有配置和通道以及节点信息
management可以做的任何事外加:
列出所有virtual hosts,包括他们不能登录的virtual hosts
查看其他用户的connections和channels
查看节点级别的数据如clustering和memory使用情况
查看真正的关于所有virtual hosts的全局的统计信息 - administrator :一切权限
policymaker和monitoring可以做的任何事外加:
创建和删除virtual hosts
查看、创建和删除users
查看创建和删除permissions
关闭其他用户的connections - None :无配置
不能访问 management plugin

